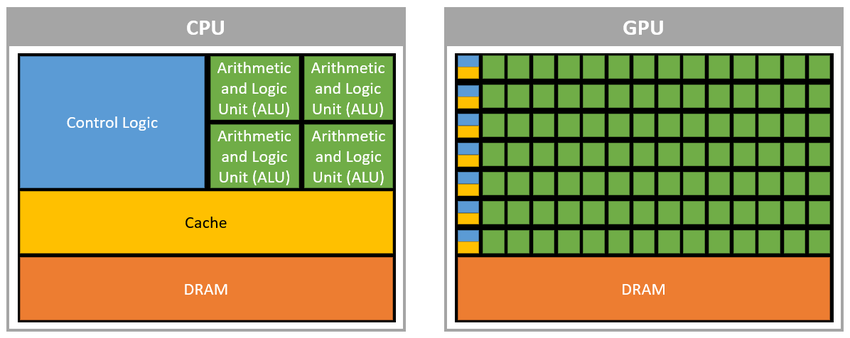
پردازندههای گرافیکی به دلیل ماهیت ساختاری و هدفی که دنبال میكنند، تواناییهای فوقالعادهای در زمینه پردازش موازی و محاسبات ممیز شناور (Floating Point) دارند و به دلیل برخورداری از هستههای پردازشی بیشتر با معماری بهینهسازی شده برای محاسبات موازی، در بسیاری از موارد قدرت محاسباتی بالاتری نسبت به CPU ارائه میدهند.
شکل زیر نمونهای از تفاوت معماریهای CPU و GPU را نشان میدهد.
 مطابق بررسیهای انجامشده، قدرت محاسباتی یک پردازنده گرافیکی تسلا، چیزی بالاتر از پانصد برابر قدرت یک پردازنده چهار هستهای اینتل است. به این نکته توجه داشته باشید که پردازندههای گرافیکی به دلیل معماری خاص و هدف یگانهای که دارند از چنین تواناییهایی برخوردار بوده و معماری آنها برای پیادهسازی یک CPU مناسب نیست. زیرا با توجه به معماری کنونی پلتفرم x86، دستگاهها و تجهیزات مختلفی در سیستم موجود هستند که مدیریت آنها بر عهده پردازنده بوده و برای حفظ ارتباطات مناسب و مدیریت جامع، CPU ناگزیر از داشتن چنین معماری و به تبع آن پردازش کندتری است. با توجه به مطالب ذکر شده و مفاهیم پایهای موازیسازی، پردازندههای گرافیکی را میتوان پردازندههایی بهینه شده در راستای موازیسازی وظایف (Task Parallelism) و دادهها (Data Parallelism) دانست.
مطابق بررسیهای انجامشده، قدرت محاسباتی یک پردازنده گرافیکی تسلا، چیزی بالاتر از پانصد برابر قدرت یک پردازنده چهار هستهای اینتل است. به این نکته توجه داشته باشید که پردازندههای گرافیکی به دلیل معماری خاص و هدف یگانهای که دارند از چنین تواناییهایی برخوردار بوده و معماری آنها برای پیادهسازی یک CPU مناسب نیست. زیرا با توجه به معماری کنونی پلتفرم x86، دستگاهها و تجهیزات مختلفی در سیستم موجود هستند که مدیریت آنها بر عهده پردازنده بوده و برای حفظ ارتباطات مناسب و مدیریت جامع، CPU ناگزیر از داشتن چنین معماری و به تبع آن پردازش کندتری است. با توجه به مطالب ذکر شده و مفاهیم پایهای موازیسازی، پردازندههای گرافیکی را میتوان پردازندههایی بهینه شده در راستای موازیسازی وظایف (Task Parallelism) و دادهها (Data Parallelism) دانست.
قدرت محاسبات قوی ریاضی GPU آن را برای استفاده در محاسبات دادههای با حجم بالا چون پردازش تصویر و ویدیو، کدگذاری و کدگشایی تصاویر و تشخیص الگو بسیار کارا كرده است. این کارایی باعث شد تا فناوریهایی برای استفاده از قدرت GPU در محاسباتی خارج از بازیها پا به عرصه وجود بگذارند و محصولات مختلفی بر پایه آنها روانه بازار شود.
فناوری CUDA (مخفف Compute Unified Device Architecture هست) از شرکت Nvidia نخستین و موفقترین فناوری این چنینی است که مفاهیم جدید بسیاری را در افزایش سرعت محاسبات با کاربردهای مختلف بر پایه استفاده از GPU مطرح كرده است. برای استفاده از پلتفرم CUDA و برنامهنویسی برای استفاده از قدرت GPU، محصولات مختلفی تولید و عرضه شدهاند که عموماً در راستای توسعه کد در محیطهای برنامهنویسی پیشرفته بهکار میروند. با این حال، کاربران بسیاری در محیطهای علمی صنعتی وجود داشتند که لازم بود بدون داشتن دانش کافی در برنامهنویسی پیشرفته، بتوانند از قدرت محاسباتی GPU و امکانات CUDA استفاده كرده و سرعت محاسبات خود را در زمینههای تحقیقاتی افزایش دهند.
برنامهنویسی موازی توسط CUDA
مزایای برنامهنویسی روی GPU موضوعی نیست که به توضیح نیاز داشته باشد. این که میتوان با استفاده از پردازندههای گرافیکی، سرعت بعضی از برنامهها را تا دهها برابر افزایش داد، در یك كلام، فوقالعاده است. با این حال، تا مدتها این مزیت بهوسیله یک مانع بزرگ محدود شد. این مانع در واقع شیوه برنامهنویسی برای GPUها بود. برنامهنویسانی که با زبانهایی مانند C، ++C ، جاوا، زبانهای مبتنی بر .NET، پایتون و بسیاری از زبانهای برنامهنویسی معمول دیگر آشنا بودند، بهطور طبیعی علاقهای به یادگیری زبان یا پلتفرم جدیدی نداشتند. آنها ترجیح میدانند که بتوانند به وسیله همین زبانها برای پردازندههای گرافیکی نیز برنامه نویسی كنند.
این دقیقاً همان چیزی است که CUDA را محبوب کرده است. با استفاده از این معماری شما میتوانید برنامه خود را با زبان C نوشته و سپس روی پردازنده گرافیکی اجرا كرده و از سرعت اجرای آن لذت ببرید. مورد مهم دیگر وجود پلتفرمی بود که بتواند روی دستگاههای مختلف اجرا شود. CUDA با این شعار که میتواند برای شما سطحی قابلقبول از کارایی و مقیاسپذیری را در یک زمان به ارمغان آورد، وارد بازار برنامهنویسی شد. درباره این معماری گفته میشود: «CUDA معماریای است که به جای محدودکردن شما توسط کارایی یک سری کتابخانه، اجازه میدهد کار مورد نظرتان را انجام دهید.» با وجود اینکه CUDA روی تراشههای گرافیكی اجرا میشود، در واقع برنامهنویسی CUDA با برنامهنویسی GPGPU تفاوت دارد. درگذشته، نوشتن نرمافزار برای GPU به این معنی بود که به زبان GPU برنامه بنویسید. در مقابل، همانطور که عنوان شد، CUDA به شما اجازه میدهد با زبانهای معمول برنامهای بنویسید که میتواند روی GPU نیز اجرا شود. همچنین به دلیل آنکه CUDA میتواند نرمافزار شما را به صورت مستقیم روی سخت افزار گرافیکی کامپایل کند، کارایی به دست آمده نیز افزایش پیدا میکند.
اما مزیت اصلی CUDA چیست؟ به طور کلی، مهمترین فایدهای که استفاده از پردازندههای گرافیکی برای توسعهدهنده در پی دارد، توانایی اجرای نخهای پردازشی بسیار زیاد در یک زمان است. به این ترتیب، اگر برنامه شما به گونهای باشد که از Taskهای بسیار زیاد و سبک تشکیل شده باشد، یعنی تعداد Taskها بسیار بالا، اما میزان نیاز آنها به پردازنده کم باشد، CUDA میتواند عملکردی خیرهکننده را برای شما به ارمغان بیاورد. البته تواناییهای کارتهای گرافیکی روز به روز در حال افزایش است. به عنوان مثال، بوردهای جدید شامل پهنای باند حافظه بالاتر، انتقال داده غیرهمزمان، عملیات اتمیک و محاسبات Floating Point نیز میشوند که میتواند دست برنامهنویس را بازتر كند.
قبل از شروع برنامهنویسی برای CUDA باید با چند موضوع آشنا شویم:
- هر برنامه CUDA در واقع برنامه سریالی است که شامل هستههای موازی میشود.
- کد سریال زبان C در درون نخهای پردازشی میزبان یا همان Thread های CPU اجرا میشود.
- هسته موازی کد C در درون تعداد زیادی از نخهای پردازشی دستگاه CUDA (یا همان نخهای پردازشی GPU) اجرا میشوند.
هسته درواقع به معنای تعداد زیادی از نخهای پردازشی همروند است. در هر زمان یک هسته روی دستگاه اجرا میشود. نکته اصلی اینجا است که هر هسته توسط تعداد زیادی از نخهای پردازشی اجرا میشود. به این ترتیب، همه نخهای پردازشی در حال اجرای یک کد هستند، اما دادههای مربوط به هر کدام متفاوت است. خود نخهای پردازشی در داخل بخشهای بزرگتری به نام بلاکهای نخپردازشی قرار میگیرند. هر هسته در واقع گریدی از بلاکهای نخپردازشی است.
بلاکهای نخپردازشی نمیتوانند با یکدیگر همزمانسازی شوند. به این ترتیب، آنها میتوانند به هر ترتیبی اجرا شوند: چه سریال و چه موازی. حال میتوان فلسفه ایجاد بلاک را درک كرد. هر بلاک در یک زمان به یک پردازنده (یا یک هسته پردازنده) نسبت دادهمیشود. پس اگر پردازنده ما چهار هسته داشته باشد، در هر زمان میتواند چهار بلاک از نخهای پردازشی را با یکدیگر اجرا كند.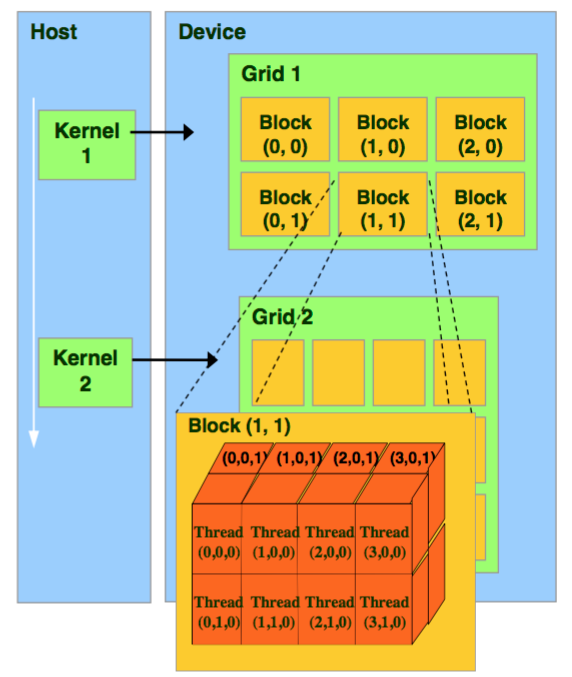
OpenCL و CUDA
OpenCL، رقیب CUDA، در سال 2009 به منظور ارائه استانداردی برای محاسبات ناهمگن که محدود به پردازندههای AMD ،Intel و Nvidia نباشد، توسط شرکت Apple و Khronos Group راه اندازی شد. در حالی که OpenCL به دلیل چند سکویی و عمومی بودن محبوب است، اما در پردازندههای Nvidia به خوبی CUDA عمل نکرده است و از بسیاری کتابخانههای یادگیری ماشین پشتیبانی نمی کند یا فقط پس از انتشار آن توسط CUDA از آن پشتیبانی می کند.